Technical Articles, Integration
Standard Model Compression in ML Pipeline
Jan 29, 2025

Amine Saboni
MLOps Engineer

Bertrand Charpentier
Cofounder, President & Chief Scientist

ML Pipelines are Complex
Building a reproducible release pipeline, for ML models, can feel like a burden. Integrating a new set of prompts, applications, or evaluation jobs often means rebuilding some part of the ML release pipeline. Adding a model compression task (such as compilation, pruning or quantization) is no exception to this rule : Will the output artifact be supported by my inference setup? What will be the accuracy cost of the speed-up increase?
To address those issues, let's dive into a model release automated pipeline, and see how we can achieve reproducibility by integrating the Pruna AI smashing process. While it applies to any types of models, we will consider LLMs as an example.
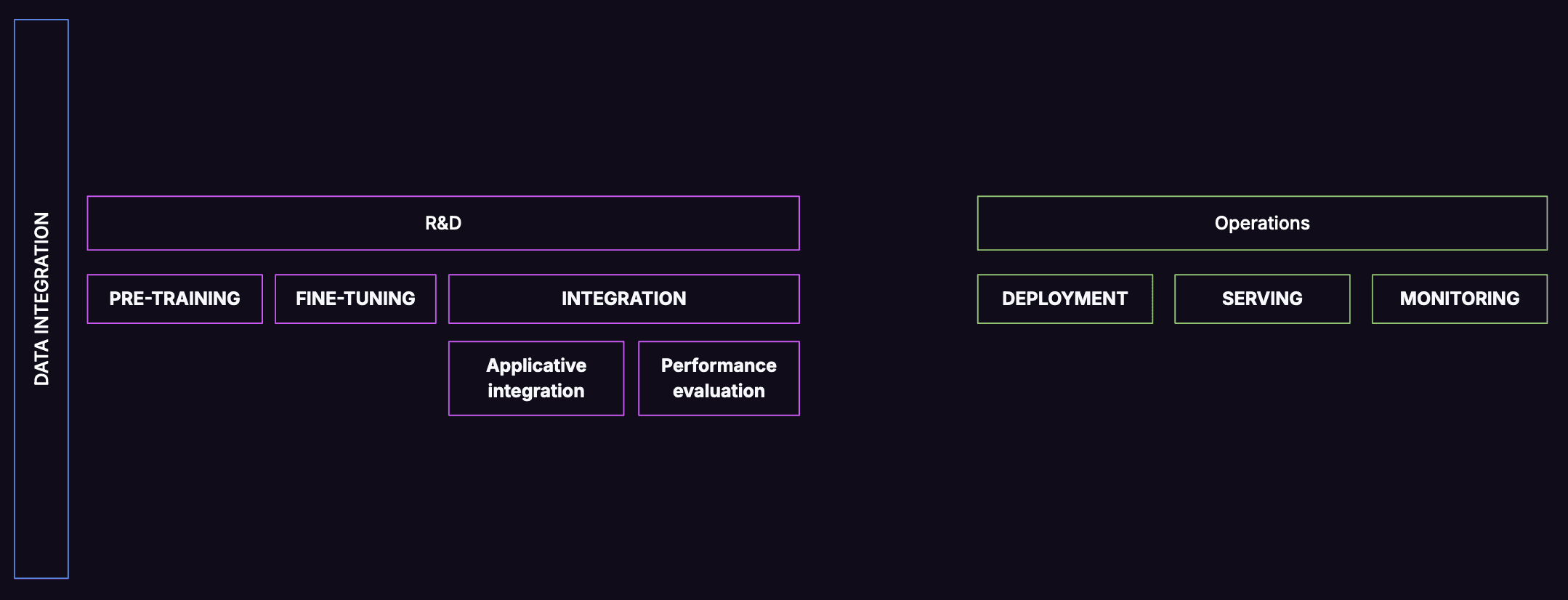
What is a ML Pipeline?
The MLOps setup defines a set of operations which composes the release pipeline (see Figure 1):
Pre-training: This step is generally outsourced to organizations with strong expertise in training procedures (e.g. Meta, Alibaba, Hugging Face or Ai2). If you are not building your own model from scratch, this step corresponds evaluating existing model architectures and sizes, with the serving setup as a constraint. Concretely, 8B parameters models might be easier to fit in the most common GPUs, as 70B ones would be harder to operate, due to the high demand of A100s chips.
Fine-tuning: By specializing a model to specific data, the operational accuracy can be dramatically increased. This step corresponds to adapting (a subset of) weights of the pre-trained model with domain-specific data that you are interested in.
Model integration: This step aims to run the model inside the applicative code along with the artifacts packaged with it (tokenizers, prompts, etc.).
After this development phase, the steps are more related to production topics :
Deployment: It corresponds to assembling all artifacts in a versioned way for usage in the inference infrastructure. The output of this step is a record in the model registry, enabling promotion in the production environment, with an automated process.
Serving: This step encompasses the infrastructure (e.g. type of GPU, scaling procedure), the inference engine (we’ll use vLLM in this article, many alternatives are spread in the industry, such as TGI or Triton for instance) and the applications which are consuming it.
Monitoring: Statistics collection about model behavior in production. Generally divided into technical (hardware state, latency, etc.) & functional ones (Distribution of labels classified, usage-related metrics, etc.). Those systems might trigger some automated retraining, or data collection for fine-tuning, and can be very specific to critical applications.
When to Compress Your ML Model?
In addition to those steps, in a post training phase, you can compress your model to make it smaller and/or faster. If some inference engines, such as TGI, enable quantization at runtime, it might be better to evaluate the model after its optimization, to validate the accuracy.
In this example, we will compress with AWQ quantization by using pruna. However, it is easy to switch to other compression methods by adapting the SmashConfig (SmashConfig Documentation)
In this step, we can define now 3 sub-tasks to be executed, manually or automatically :
Set the compression configuration. In our example, it would use AWQ configuration.
Effectively compress the base model.
Evaluate the compressed model with comparison with the base model
These subtasks can be integrated in your existing ML pipeline:

As adapting the compression process to a new model is now limited to its configuration step, its integration in the overall pipeline could be done seamlessly, for instance using the following Docker packaging:
The deployment phase can be directly chained, using vLLM for instance, loading the compressed model as any other artifact :
With this packaging approach, the optimization process can be run on various engines, from GitHub Actions to any orchestration manager, enabling reuse with a minimal configuration change. Using Pruna, you can easily search for an optimal compression configuration, which can be done automatically soon in a coming release!
Want to know how to adapt the pipeline to your use case? Check-out the tutorials from our documentation, or directly from the blog :



・
Jan 29, 2025
Subscribe to Pruna's Newsletter