Technical Articles, Integration
Accelerating Image Generation: Going Beyond API Optimization from FAL, Replicate, Together, Fireworks
Mar 24, 2025

Nils Fleischmann
ML Research Engineer

John Rachwan
Cofounder & CTO

Bertrand Charpentier
Cofounder, President & Chief Scientist

Quentin Sinig
Go-to-Market Lead

Accelerating Image Generation x2-3! Going Beyond API Optimization from FAL, Replicate, Together, Fireworks.
One major concern with recent image-generation models is that, while they produce amazing results, they are often too slow for some use-cases. Generating a single high-resolution image can take over 10 seconds, which presents a pain point for many applications. AI model API providers such as Replicate, fal, together.ai, and Fireworks AI have already recognized this need and are now engaged in fierce competition to deliver the fastest inference endpoint. By no coincidence, speed is the first attribute that fal, Fireworks AI, and Replicate mention in their FLUX announcements. In this blog, we aim to answer the following questions:
Are AI model API provider already using compression techniques to accelerate the models?
How good are the used compression techniques by AI model API provider and can we even measure the difference to the base model?
How does the Pruna compression compare against compression done behind API?
While Pruna does not provide AI model API, we aim to give insights on the cool compression techniques that could be applied behind API to accelerate generative AI models :)
The “Jumping Cat Test”
With the appropriate compression methods, it is possible to accelerate image generation 2-3x. While it is hard to observe visual differences on a single image, slight differences can become apparent when considering a lot of images.
The Fréchet inception distance (FID) is used in scientific papers (e.g. the original diffusion paper) to compare images in a reference dataset to the images produced by a generative model. In our setting, we can use it to compute the distance between images produced by the original model and images from API’s serving the same model. A low FID means that the served model is identical to the base model while a high FID indicates that the served model is different from the base model.
Cost per Image* | Pricing Model | Resource | |
|---|---|---|---|
Replicate | 0.025$ / image | Fixed Price per image | https://replicate.com/black-forest-labs/flux-dev |
Replicate [go_fast] | 0.025$ / image | Fixed Price per Image | https://replicate.com/black-forest-labs/flux-dev |
fal | 0.025$ / image | Fixed Price per Megapixel | https://fal.ai/pricing |
together.ai | ~0.045$ / image | Fixed Price per Step | https://www.together.ai/pricing |
Fireworks A [FP8] | 0.025$ / image | Fixed Price per Step | https://fireworks.ai/blog/flux-launch |
*1024×1024 images with FLUX [dev] using 50 inference steps
Unfortunately, one needs thousands of images to compute the FID reliably. Considering that generating a single image via an API costs between 0.025-0.05 dollar (see pricing table), this would have blown the budget for this blog post ;) To reduce the number of required images for the FID, we only considered images for a single prompt. We ended up using our favorite prompt, “a cat jumping in the air to catch a bird” from Google’s PartiPrompt dataset, which kindly donated the name for this test.

On the state-of-the-art FLUX [dev] model for text generation, we compare the following baselines:
Since FLUX [dev] is an open-weights model, we run the base model locally to generate 300 images of cats jumping. These images, generated at 1024×1024 resolution using 50 inference steps and the default guidance scale of 3.5, serve as reference images.
Using the same settings as above, we generated 300 images for each of the following APIs:
Replicate’s black-forest-labs/flux-dev API with go_fast=False
Replicate’s black-forest-labs/flux-dev API with go_fast=True
fal’s fal-ai/flux/dev API
Fireworks AI’s Black Forest Labs / FLUX.1 [dev] FP8 API
together.ai’s black-forest-labs/FLUX.1-dev API (Note: together.ai’s API does not support customizing the guidance scale, so we assume it uses the default value of 3.5)
We also generated 300 images using a compressed version of FLUX [dev] obtained by applying Pruna’s auto-caching that gives a 1.95x speed up (measured on an NVIDIA L40S GPU).
For each endpoint, we measured the average time per request and plotted the FID against these times. The measured inference times depend on the specific hardware used by each provider, which we do not know in detail. Additionally, external factors such as queuing times and network latency may have influenced the results.
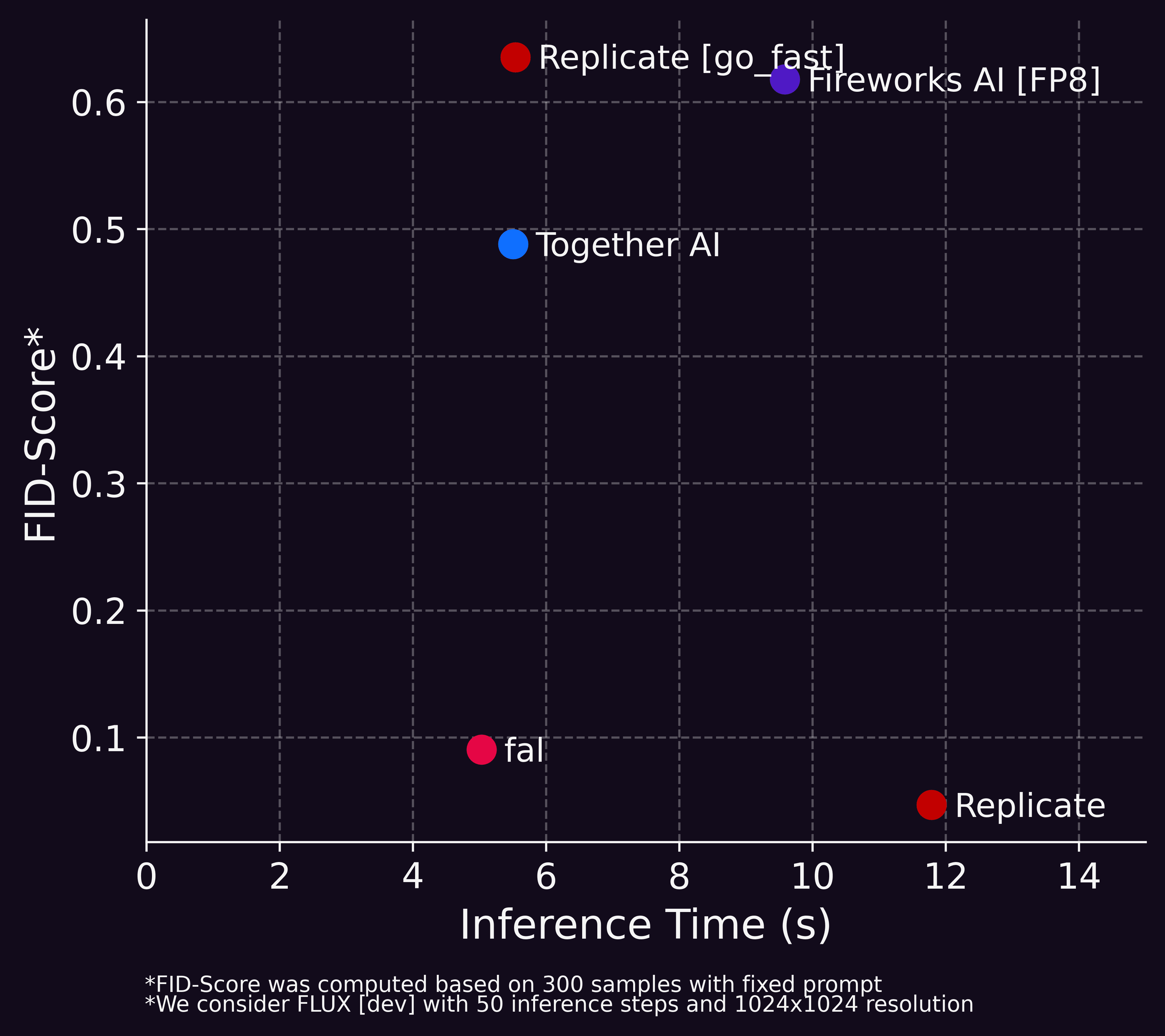
Given the low FID score, we believe that Replicate (with go_fast=false) serves the original model without any optimizations. Its approximately 12-second inference time provides an estimate of how long it takes to run the base Flux model on modern GPUs. While we are not sure what GPU they use, this duration aligns with our experience running FLUX [dev] on an H100 SXM5 GPU.
The fact that the other APIs reduce inference time by up to 45% suggests that they optimize the model. Using the “jumping cat test,” we can observe that these changes also affect the model outputs. Images generated by Replicate (go_fast=true), Fireworks AI FP8, and Together AI have a significantly higher FID compared to those from Replicate (go_fast=false) and fal’s API.
We can also compute the Fréchet Inception Distance (FID) between images generated by different APIs to assess their similarity. Notably, the outputs from Firework AI’s FP8 API and Replicate’s go_fast API are remarkably similar according to the FID metric, suggesting they employ the same quantization approach. Similarly, Together AI’s API produces outputs that closely match these results, which may indicate that it too uses some form of quantization.

Key Takeaways:
Most of the APIs we tested seem to employ optimization techniques to improve inference time for FLUX [dev]. We were able to measure differences in generated outputs using the “jumping cat” test.
Our tests indicate that the outputs from Replicate’s go_fast API and Fireworks AI’s FP8 API deviate the most from the original model, while the fal’s API and Pruna’s auto-caching method produce images that remain closer to the original.
The “jumping cat test” can be used to determine similarities among the outputs of different APIs. Our results suggest that Replicate’s go_fast and Firework AI’s FP8 endpoint use similar, if not identical compressed models.
A comparison in Image Fidelity
It is important to emphasize that the “jumping cat test” measures only differences in the distribution of generated images, making it unsuitable for assessing image fidelity. A common method to evaluate the quality of a compressed model is to display its images alongside the original. Replicate makes this comparison easy by hosting a website that showcases the side-by-side comparisons. Have a look for yourself - it is surprisingly difficult to spot any differences.
While visually comparing images can offer good intuitive insights, we prefer metrics like LPIPS, SSIM, and PSNR that objectively measure image fidelity, allowing easy comparison between approaches. We took the first 100 image pairs from Replicate’s websites and computed these metrics for them. Then we configured our proprietary Auto Caching algorithm to match the speed up of “go_fast” and computed these metrics for the same prompts. The results are shown below:
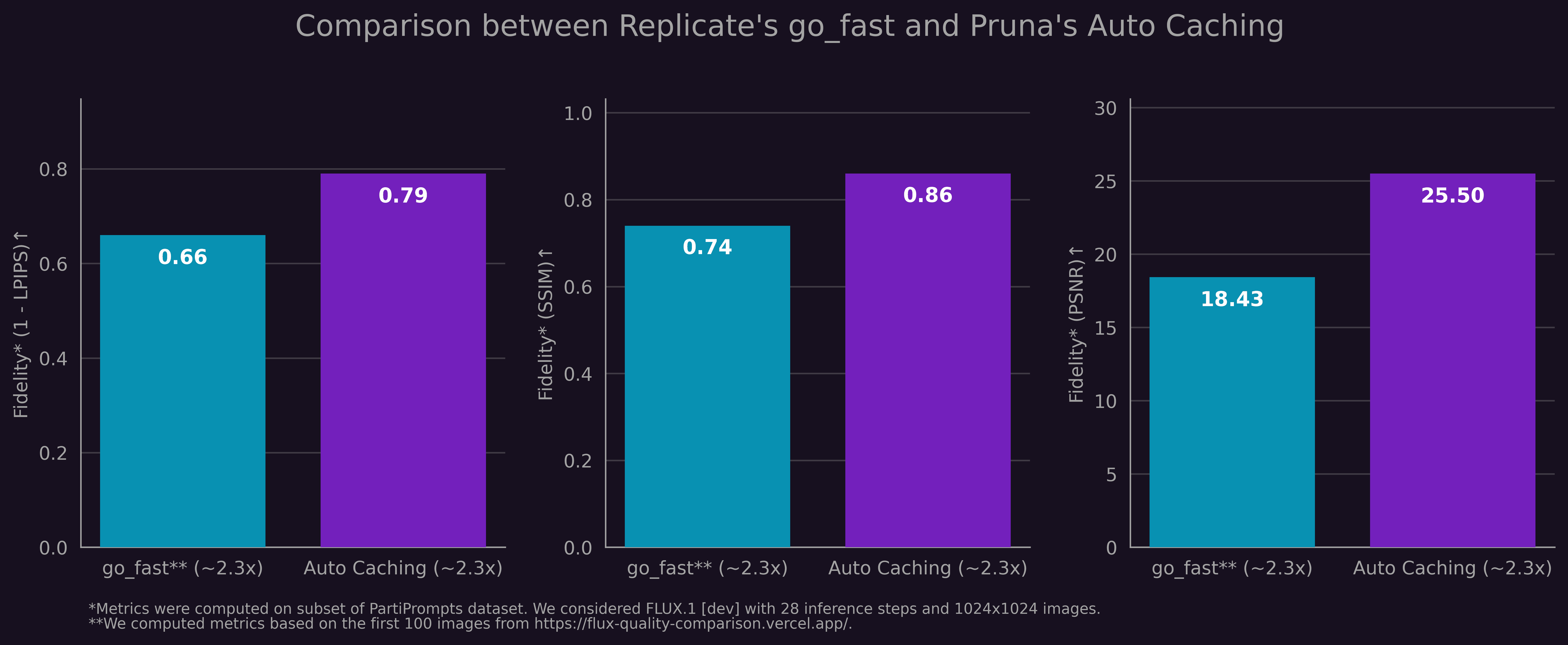
Across all metrics, the model compressed with our Auto Caching outperforms Replicate’s “go_fast” compression while delivering a similar relative speed up.
Conclusion
The leading image generation APIs already use compression techniques to deliver fast inference to their customers. When communicated transparently, this is a win-win situation: API providers benefit from higher efficiency, and users get their images faster with barely any change in the output. However, not all compressed models are created equal:
Images generated using Replicate’s go_fast, Fireworks AI’s FP8, Together AI and fal’s API might deviate from the base model to obtain faster generation time.
We also computed image fidelity metrics for Replicate’s go_fast API and found that Pruna’s Auto Caching outperforms it while giving the same relative speed up.
If this post got you interested in the compression techniques employed by major API providers, we have got you covered. We just open-sourced a part of our optimization engine to help you get started compressing your models. And if you’re looking to experiment with the Auto Caching method discussed here, as well as other state-of-the-art compression approaches, our Pruna Pro version could be interesting to you.



・
Mar 24, 2025
Subscribe to Pruna's Newsletter