Technical Articles, Integration
An Introduction to AI Model Optimization Techniques
Apr 18, 2025

David Berenstein
ML & DevRel

Bertrand Charpentier
Cofounder, President & Chief Scientist

An Introduction to AI Model Optimization Techniques!
Pruna AI is the AI optimisation engine for ML teams seeking to simplify scalable inference. The toolkit is designed with simplicity in mind - requiring just a few lines of code to optimize your models. It is open source and aims to achieve better models on the following fronts:
Faster: Accelerate inference times through advanced optimisation techniques
Smaller: Reduce model size while maintaining quality
Cheaper: Lower computational costs and resource requirements
Greener: Decrease energy consumption and environmental impact
In this blog, we present the key techniques to achieve these four goals. Let’s take a look at the an overview of techniques implemented in our library before diving into each of them in more depth.
Optimisation Techniques
To get started, we created a high level overview of different techniques that are implemented in Pruna. This is a limited list of different optimization techniques, and could be enriched further, however, it forms a solid basis your understanding.
Technique | Description | Impacts |
|---|---|---|
Batching | Groups multiple inputs together to be processed simultaneously, improving computational efficiency and reducing overall processing time. | Speed (✅), Memory (❌), Accuracy (~) |
Caching | Stores intermediate results of computations to speed up subsequent operations, reducing inference time by reusing previously computed results. | Speed (✅), Memory (~), Accuracy (~) |
Speculative Decoding | Speculative decoding speeds up AI text generation by having a small, fast model predict several tokens at once, which a larger model then verifies, creating an efficient parallel workflow. | Speed (✅), Memory (❌), Accuracy (~) |
Compilation | Compilation optimises the model with instructions for specific hardware. | Speed (✅), Memory (➖), Accuracy (~) |
Distillation | Trains a smaller, simpler model to mimic a larger, more complex model. | Speed (✅), Memory (✅), Accuracy (❌) |
Quantization | Reduces the precision of weights and activations, lowering memory requirements. | Speed (✅), Memory (✅), Accuracy (❌) |
Pruning | Removes less important or redundant connections and neurons, resulting in a sparser, more efficient network. | Speed (✅), Memory (✅), Accuracy (❌) |
Recovering | Restores the performance of a model after compression. | Speed (~), Memory (~), Accuracy (🟢) |
✅(improves), ➖(stays the same), ~(could worsen), ❌(worsens)
Technique requirements and constraints
Before we continue, note that each one of these techniques and their underlying implementation algorithms have specific requirements and constraints. Some techniques can only be applied on certain hardware like GPUs, or models like LLMs or image generation models. Others might require a tokeniser, processor, or dataset to function. Lastly, not all techniques can be used interchangeably, and therefore have compatibility limitations.
The Optimisation Techniques
We will now dive a bit deeper into different optimisation techniques. Although we will dive a bit deeper into the various techniques and their underlying algorithms we will not be going into the nitty gritty details and keep it high level and for each technique highlight one of the fundamental underlying algorithms that has been implemented in the Pruna library.
Batching AI model inference
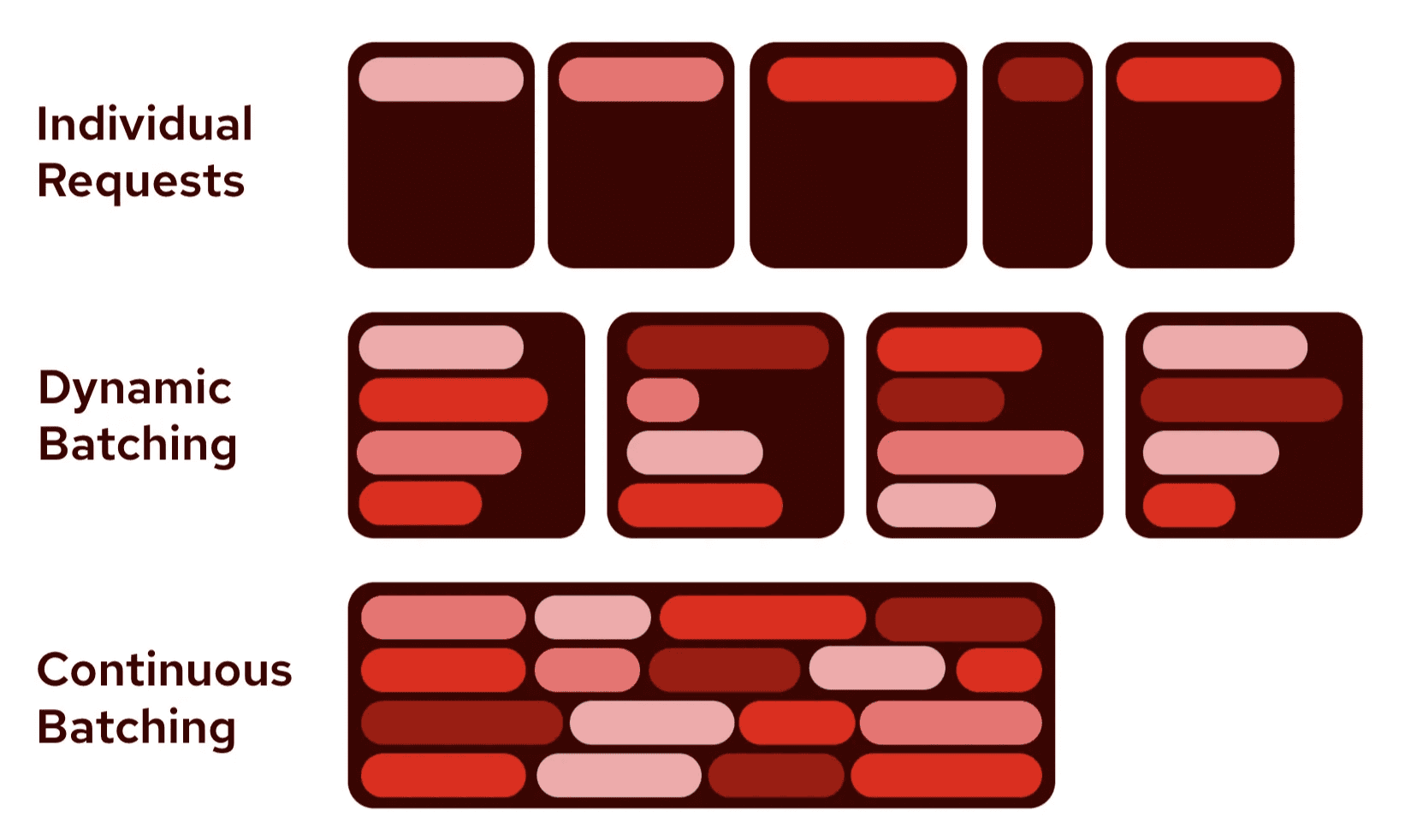
Batching groups multiple inputs together to be processed simultaneously, improving computational efficiency and reducing overall processing time. Instead of processing one prompt at a time, the GPU processes multiple prompts in parallel, maximising hardware utilisation. This significantly increases throughput since modern GPUs are designed for parallel computation. Batching reduces the per-example computational overhead and allows for better distribution of fixed costs across multiple inputs, thus often increasing the throughput.
For batching, we implemented WhisperS2T, which works on top of whisper models. It intelligently batches smaller speech segments and is designed to be exceptionally fast than other implementation, boasting a 2.3X speed improvement over WhisperX and a 3X speed boost compared to HuggingFace Pipeline with FlashAttention 2 (Insanely Fast Whisper).
Caching intermediate results
Caching stores intermediate results of computations to speed up subsequent operations, reducing inference time by reusing previously computed results. For transformer-based LLMs, this typically involves storing key-value pairs from previous tokens to avoid redundant computation. When generating text token by token, each new token can reuse cached computations from previous tokens rather than recomputing the entire sequence. This dramatically improves inference efficiency, especially for long-context applications. However, caching go beyond only saving KV computations, and can be used in multiple places for LLMs and image generation models.
For caching, we implemented DeepCache, which works on top diffuser models. DeepCache accelerates inference by leveraging the U-Net blocks of diffusion pipelines to reuse cached high-level features. The nice thing is that it is training-free and almost lossless, while accelerating models 2X to 5X.
Speculative decoding with parallelising generation
Speculative decoding improves the efficiency of language model inference by parallelising parts of the generation process. Instead of generating one token at a time, a smaller, faster draft model generates multiple candidate tokens in a single forward pass. The larger, more accurate model then verifies or corrects these tokens in parallel, allowing for faster token generation without significantly sacrificing output quality. This approach reduces the number of sequential steps required, lowering overall latency and speeding up inference. It’s important to note that the effectiveness of speculative decoding depends on the alignment between the draft and target models, as well as the chosen parameters like batch size and verification strategy.
For speculative decoding, we have not implemented any algorithms. Yet! Stay tuned to discover our future speculative decoding algorithms.
Compilation for specific hardware
Compilation optimises the model for specific hardware by translating the high-level model operations into low-level hardware instructions. Compilers like NVIDIA TensorRT, Apache TVM, or Google XLA analyse the computational graph, fuse operations where possible, and generate optimised code for the target hardware. This process eliminates redundant operations, reduces memory transfers, and takes advantage of hardware-specific acceleration features, resulting in faster inference times and lower latency. it is important to notice that each combination of model/hardware would have a different optimal compilation setup.
For compilation, we implemented Stable-fast, which work on top of diffuser models. Stable-fast is an optimization framework for Image-Gen models. It accelerates inference by fusing key operations into optimized kernels and converting diffusion pipelines into efficient TorchScript graphs.
Distillation for smaller models
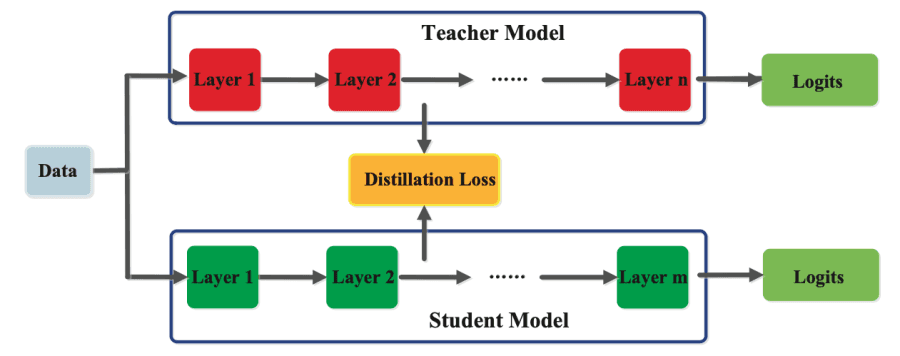
Distillation trains a smaller, simpler model to mimic a larger, more complex model. The larger "teacher" model produces outputs that the smaller "student" model learns to replicate, effectively transferring knowledge while reducing computational requirements. This technique preserves much of the performance and capabilities of larger models while significantly reducing parameter count, memory usage, and inference time. Distillation can target specific capabilities of interest rather than general performance.
For distillation, we implemented Hyper-SD, which works on top of diffusion models. Hyper-SD is a distillation framework that segments the diffusion process into time-step groups to preserve and reformulate the ODE trajectory. By integrating human feedback and score distillation, it enables near-lossless performance with drastically fewer inference steps.
Quantization for lower precision
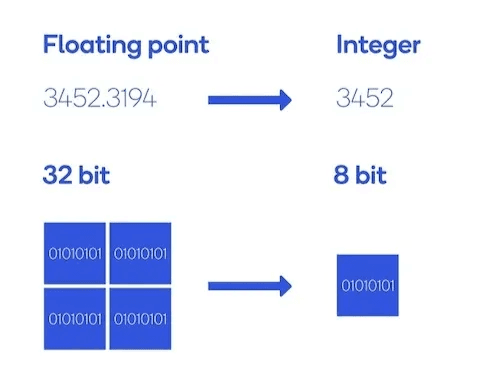
Quantization reduces the precision of weights and activations, lowering memory requirements by converting high-precision floating-point numbers (FP32/FP16) to lower-precision formats (INT8/INT4). This reduces model size, memory bandwidth requirements, and computational complexity. Modern quantisation techniques like Post-Training Quantisation (PTQ) and Quantisation-Aware Training (QAT) minimise accuracy loss while achieving substantial efficiency gains. Hardware accelerators often have specialised support for low-precision arithmetic, further enhancing performance.
For quantization, we implemented Half-Quadratic Quantization (HQQ), which works on top of any model. HQQ leverages fast, robust optimization techniques for on-the-fly quantization, eliminating the need for calibration data and making it applicable to any model. This algorithm is specifically adapted for diffusers models.
Pruning away redundant neurons
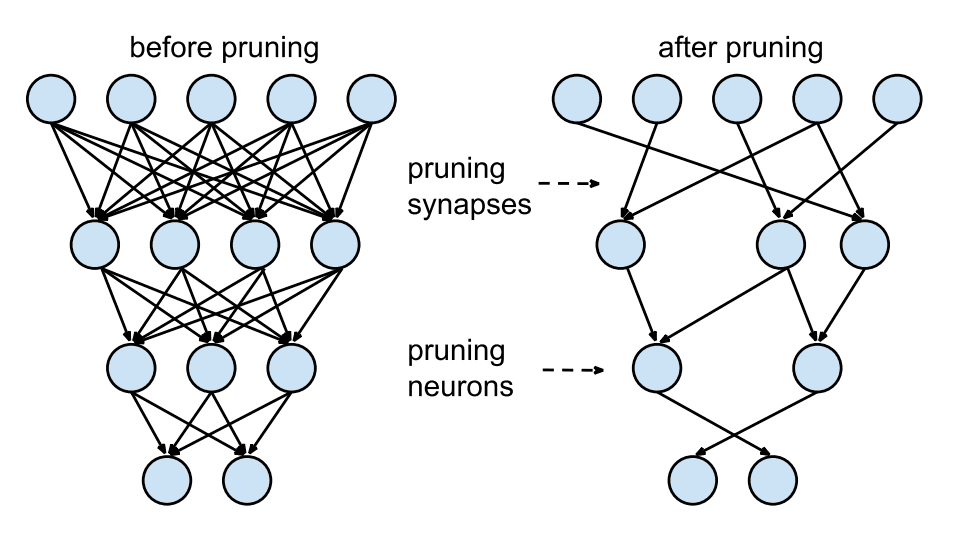
Pruning removes less important or redundant connections and neurons, resulting in a sparser, more efficient network. Various pruning strategies exist, including magnitude-based pruning (removing smallest weights), and lottery ticket hypothesis approaches (finding sparse subnetworks). Key design choices are usually which structure to prune (e.g. weight, neuron, blocks) and how to score structures (e.g. using weight magnitude, first order, second order information). Pruning can reduce model size significantly (often 80-90%) with minimal performance degradation when done carefully. Sparse models require specialised hardware or software support to realise computational gains.
For pruning, we implemented structured pruning, which works on top of any model. Structured pruning removes entire units like neurons, channels, or filters from a network, leading to a more compact and computationally efficient model while preserving a regular structure that standard hardware can easily optimize.
Recovering performance with training
Recovering is special since it allow so improve performance of compressed models. After compression, it restores the performance of a model through techniques like fine-tuning or retraining. After aggressive pruning, models typically experience some performance degradation, which can be mitigated by additional training steps. This recovery phase allows the remaining parameters to adapt and compensate for the compression. Approaches for efficient recovery include learning rate rewinding, weight rewinding, and gradual pruning with recovery steps between pruning iterations. The recovery process helps achieve optimal trade-offs between model size and performance.
For recovering, we implemented text-to-text PERP, which works on top of text generation models. This recoverer is a general purpose PERP recoverer for text-to-text models using norm, head and bias finetuning and optionally HuggingFace’s LoRA. Similarly, we support text-to-image PERP for other image generation models.
What’s next?
This was a brief introduction to each one of these categories and there are many more nuances, techniques and implementations to highlight. The cool thing is, that each one of these techniques has been implemented in the open source Pruna library and is ready for you to play around with! Don’t forget to follow us on socials and join the movement to make your AI model cheaper, faster, smaller, greener!


・
Apr 18, 2025
Subscribe to Pruna's Newsletter